Due to the disparate nature of data, analytics, and technology in different organizations, the optimal big data deployment strategy may differ for every organization.
Therefore, a customized strategy that is specific to the organization should be drafted for deploying big data technologies without any disruption. A detailed assessment of integration and interoperability, security, governance, and processes should be made before the deployment. All the deliverables should be defined and artifacts made available for seamless implementation.
The objective of this paper is to enable the decision makers to adopt a comprehensive approach while deploying big data technologies and processes in their organizations.
The age of big and smart data
We are in the age of big data where organizations are exploring ways to store, manage, and harness large amounts of data effectively. With an intention to improve their operations and make informed business decisions, they are applying analytics to convert data into actionable insights. With the help of intelligent algorithms, the attempt is to make data smart so that it can send patterns and signals for informed decision making. This will eventually result in significant reduction of operational cost and increase profit.
The think tank at the USA’s leading health insurance company and Fractal Analytics planned rigorously for eight weeks before successfully deploying big data technologies within the former’s infrastructure.
Immense expertise, however, is required to select and deploy the right combination of big data technologies that enhance operations and address specific business needs. There is a plethora of technology offerings in the market that solve specific problems within big data environments. Moreover, these technologies are evolving at a rapid pace to offer greater efficiency and solve more complex problems. To make the best of these technologies, it is important to assess the existing data and infrastructure, and compare with the industry benchmarks to identify the gaps. It is also essential to articulate the key performance indicators to be achieved and draft a detailed big data deployment and adoption plan tailored for the organization.
Taking the plunge without adequate knowledge and a foolproof big data strategy can result in failure. Ill-informed decisions and flawed deployment roadmaps can drain budgets and have an undesired impact on business performance.
Big data deployment framework
There are several factors that influence the decisions to deploy big data technologies in an organization.
- Factor: Presence of unstructured and/or non-traditional data in the system
Examples: Web chats, call center transcripts, digital notes and records, web metrics - Factor: Dealing with a huge volume of data that runs into petabytes or zettabytes
Examples: Social media data, calls, web chats, web logs, mobile devices data - Factor: Flow of ultra-low latency data
Examples: Social media and blog comments, recent calls and chats, web adoption, user authorization information - Factor: Need for real-time scoring and insights
Examples: Authorization triggers, incoming calls - Factor: Exploring new analytics algorithms
Examples: Text mining, predictive models, probabilistic learning algorithms, unsupervised learning methods, Bayesian algorithms, neural networks
Data, analytics, and technology are the three main pillars of the big data landscape.
However, not all pillars are equally strong in every organization. Some organizations have structured data with known latency and volume, but have no means to perform analytics with it. Others may have all the analytical tools in place, but no control over managing data. There may be yet others that have control over data and analytics, but are unable to harness the insights for decision making due to outdated technology infrastructure.
These three pillars are integrated and further reinforced with security, governance, and processes. The following illustration depicts:
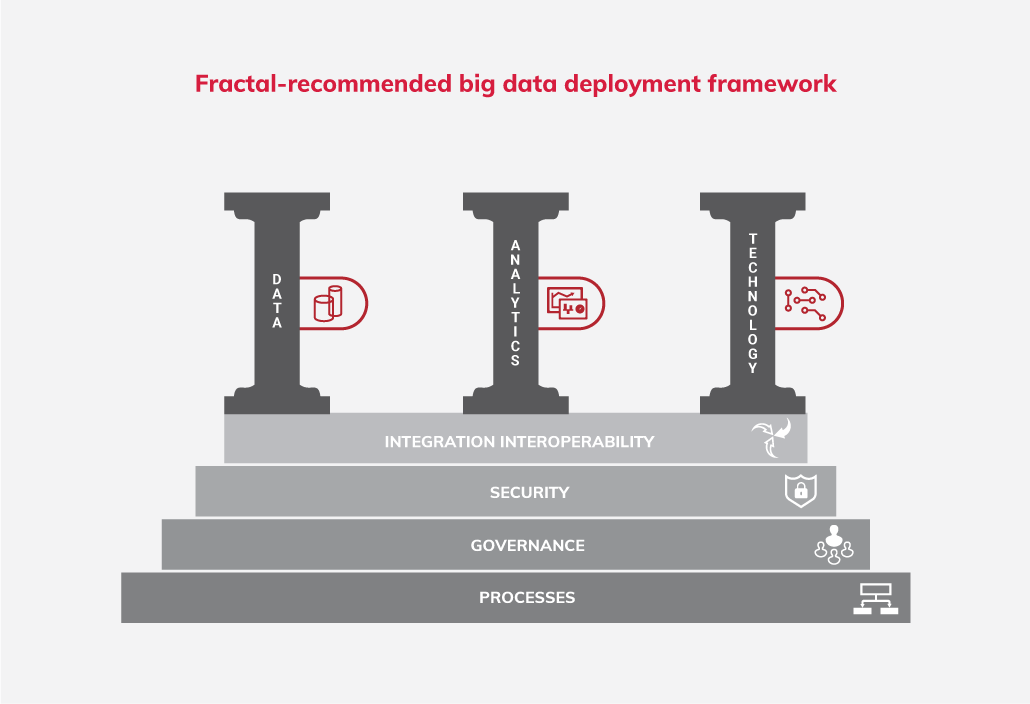
In the subsequent sections, let us delve deeper to decipher this framework
Data
Data is at the heart of analytics, technology, and informed decision making. Its shape, volume, and latency determine the breed of big data technologies to be deployed in the organization. Meticulous mapping of data properties, sources, and frequencies is important while drafting the deployment strategy.
Data from existing and new sources may be dealt with differently. Besides, there may be different methods to manage transactional and non-transactional data. How structured the data is also influences the deployment decisions. Data’s format, its ability to interact with other data and databases, and its consistency should be thoroughly assessed. Other factors, such as write throughput, data-source prioritization, event-driven message input, data recoverability, fault tolerance, high performance deployment, platform availability, and automation, also need to be considered while strategizing.
Data is at the heart of analytics, technology, and informed decision making. Its shape, volume, and latency determine the breed of big data technologies to be deployed in the organization.
A combination of traditional technologies that are in use (such as relational databases) and big data technologies (such as Apache Hadoop and NoSQL) might be the apt solution for some organizations to achieve their business objectives. For others, adopting new technologies altogether would be the best solution.
Analytics
Analytics may involve developing and operationalizing descriptive, predictive, text mining, and unsupervised learning models leveraging data sources. Developing an analytical capability in a big data environment involves understanding how it would support the following:
- Data processing, querying, aggregation, and transformation
- Structured query language (SQL) and native programming languages
- Human-acceptable query latency
- Text mining and processing
- Supervised and unsupervised algorithms
- Interoperability with other platforms and analytical tools
Apart from these factors, the analytical models should ideally offer features such as ease of use (coding, debugging, and packaging), open source libraries and application programming interfaces (APIs), and graphical interfaces for visualization. Operationalizing analytics may typically involve assessing fault tolerance and automated recovery of data processing jobs, setting standardized parameters such as dates and strings across platforms, seamless scheduling of jobs, logging, and monitoring.
Analytics may involve developing and operationalizing descriptive, predictive, text mining, and unsupervised learning models leveraging data sources.
To operationalize analytics, a combination of traditional technologies that are in use (such as SAS, R, Python server) and a distributed environment for big data could possibly be the best solution for some organizations to achieve their business objectives.
Technology
The existing infrastructure in the organization may have limitations to solve complex data problems. It is important to study the existing software and hardware to identify the gaps that can be filled with new technologies and systems.
The organizations should assess their networking, server, storage, and operations infrastructure thoroughly before deploying big data technologies. Besides, the nature of data processing—real-time or batch— also drives the infrastructure needs to a considerable degree. This in turn determines if the infrastructure needs to be commissioned on cloud, dedicated servers, or a combination of both.
It is important to study the existing software and hardware to identify the gaps that can be filled with new technologies and systems.
Speed, performance, scalability, and costs are other important factors that can influence the decisions around investments in big data infrastructure.
Lastly, it is of utmost importance to map the technology infrastructure with human skills for deploying and using it.
Integration and interoperability
Big data technologies should be integrated into the existing infrastructure in a seamless fashion to avoid any disruption, business downtime, and cost overruns.
Initially:
Data storage and operationalization can happen in both traditional and big data environments, whereas analytics can remain exclusive to the traditional environment. This will provide a certain level of cost optimization.
Gradually:
Some analytics can happen in both the environments, thereby providing additional cost savings.
Finally:
Data storage and analytics can happen in both the environments with operationalization becoming exclusive to the big data environment. This will optimize cost significantly.
Big data technologies should be integrated into the existing infrastructure in a seamless fashion to avoid any disruption, business downtime, and cost overruns.
Various databases, clusters, and nodes should be studied for integration. Other important considerations are metadata and master data management (MDM), extract-transform-load (ETL) preprocessing, data retention, framework for faster deployment with automation, and scalability.
At the organizational level, inter-departmental, cross-project, and multi-platform integration of big data technologies should be planned early on, as it may get difficult to achieve this later.
Security
Security and privacy have become major concerns with the advent of cloud, diversified networks and data sources, and the variety of software platforms. As the organization’s data and infrastructure become more accessible from different platforms and locations, they also become vulnerable to hacking and theft risks.
Security and privacy have become major concerns with the advent of cloud, diversified networks and data sources, and the variety of software platforms.
Traditional security methods and procedures that are suitable for smallscale static data may be inadequate to fortify big data environments.
Amongst several security considerations, big data deployment strategy should most importantly encompass the following:
- Securing all the applications and frameworks
- Isolating devices and servers containing critical data
- Introducing real-time security information and event management
- Providing reactive and proactive protection
Finer details of configuring, logging, and monitoring data and applications should be known beforehand to implement the security measures.
Governance
Data governance involves having access to audit reports and reporting metrics. The scope of governance should be clearly defined while commissioning the big data environment.
The following are certain important considerations for governance:
- Defining the frequency of refreshing and synchronizing metadata
- Identifying possible risk scenarios along with failovers
- Instilling quality checks for each data source loaded and available within the big data environment
- As per the regulations and business needs, disposing of the assets that are no longer required
- Defining guidelines for acceptable use of social media data of existing and potential customers
- Scheduling audit logging of events along with defined metrics
- Productionizing a logging framework for data access, and creation and update of intermediate datasets to generate logs of event runs and identify failures/errors during production run and analytic operations
- Identifying access patterns across data folders and defining access control rules based on hierarchy (groups, teams, and projects)
Data governance involves having access to audit reports and reporting metrics. The scope of governance should be clearly defined while commissioning the big data environment.
Processes
Adopting big data technologies requires a shift in the organization’s way of functioning because it changes the operations of the business. The deployment should be manageable and timely, integrate into the broader enterprise architecture, and involve specialized personnel.
Processes to implement, customize, populate, and use the big data solutions are necessary. Methodologies to control the flow of data into and out of the big data environment should be defined. Furthermore, processes to provide feedback for improvements during big data infrastructure deployment and thereafter should be in place.
Insights in the big data environment
Data, analytics, and technology have an impact on the consumption of insights for making informed business decisions. Using tools and technology, analytics performed on data provides insights that determine how users and applications will access, interpret, and consume the output of analytics performed on data. Having maximum visibility of the analytical output will enable effective decision making and optimize business outcomes.
Visualizing the output provides the ability to effectively consume aggregated and granular data. Factors such as connecting to multiple data processes and look-up engines, and interfacing with databases and warehouses to push output for downstream consumption should be considered. Furthermore, the ability to modify a reporting module and add new dimensions to it will enhance the output and decision making in a big data environment.
A Fortune 500 Global company got an analytics solution developed for surveillance monitoring to identify anomalies in real time by processing streaming data. The solution also provided an interface for retroactive analysis on large historic datasets.
While planning for the consumption of insights in a big data environment, the constraints and opportunities of the underlying systems should be considered. On one hand, the infrastructure should be configured to provide quick (realtime) insights. On the other, provisions should be made for greater processing times for certain insights that are derived from large datasets.
Other important factors to be considered while distributing the output should be the frequency of consumption, the extent of personalization, access through APIs, message pushing ability, and reusability.
Concluding note
Intensive, comprehensive, and persistent planning is imperative for deploying big data technologies in any organization. With the changing landscape of big data technologies, the strategy itself should evolve to accommodate such changes. The deployment strategy is more than a piece of paper. It is a mechanism to deploy big data technologies within the existing infrastructure for maximum impact without affecting the core business.
Intensive, comprehensive, and persistent planning is imperative for deploying big data technologies in any organization.
The effort invested at the initial planning stage might determine the success or failure of the deployment, and in many cases, of the organization itself. The nuts and bolts of every aspect of deployment should be fine-grained. Stakeholders from different departments should be involved and a collaborative environment should be created. A roadmap with the deployment phases should be drafted and made handy.
The effort invested at the initial planning stage might determine the success or failure of the deployment, and in many cases, of the organization itself.
The following should be the typical outcome of a detailed assessment that will help in formulating the big data deployment strategy:
- Big data architecture diagrams
- Data flow diagrams
- Logical architecture diagrams with detailed explanation of the inherent layers
- Technology mapping diagrams
- Process flows of operational patterns
- Reference architecture diagrams for the inherent scenarios
Reference architecture diagrams for the inherent scenarios
- Deployment recommendations
- Deployment phases
- All the activities within the deployment phases
- Human skill mapping
These artifacts of strategy and roadmap collectively form a construct for deploying big data technologies. Each one plays an important role in articulating, tracking, and controlling the deployment. These are must-have for any organization seeking a successful deployment and therefore, should be tailored carefully.
Finally, as deployment of big data technologies can be a complex task, organizations need to realistically assess what to execute in-house and where to take the help of external partners.
Finally, as deployment of big data technologies can be a complex task, organizations need to realistically assess what to execute in-house and where to take the help of external partners. Collaborating with partners can provide access to a proficient talent pool, improve utilization rates, reduce cost, and offer the much needed strategic direction for successful deployment.
About Author
Suraj Amonkar – Director (Big Data and Visualization) at Fractal Analytics
Vishal Rajpal – Director (Global Consulting) at Fractal Analytics
Acronyms
- API – Application programming interface
- ETL – Extract, transform, load
- SAS – Statistical analysis software
- SQL – Structured query language
- USA – United States of America